Regularization
Regularization helps to keep weights and/or biases small in your network. Some regularization methods also make sure that you are not overfitting your data.
Dropout
Enabling dropout will randomly set the activation of a neuron in a network to 0
with a given probability.
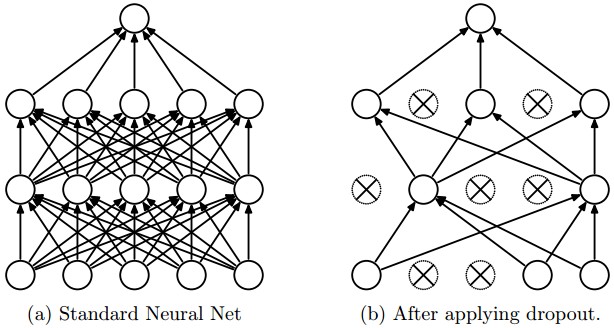
Only use dropout when you are working with large datasets that may show some noise. Dropout is a method that prevents overfitting, but it shouldn't work on datasets like XOR or SINUS, as they don't have any noise. Dropout can only be used during training:
myNetwork.train(myTrainingSet, {
error: 0.03,
iterations: 1000,
rate: 0.3,
dropout: 0.4 // if you're not sure, use 0.5
});
Setting the dropout to 0.4 means that 40% of the neurons will be dropped out
every training iteration. Please note that Neataptic has no layered network
architecture, so dropout applies to the complete hidden area.
Momentum
Momentum simply adds a fraction m of the previous weight update to the current one. When the gradient keeps pointing in the same direction, this will increase the size of the steps taken towards the minimum. It is therefore often necessary to reduce the global learning rate µ when using a lot of momentum (m close to 1). If you combine a high learning rate with a lot of momentum, you will rush past the minimum with huge steps! Read more about it here.

you can use this option during training:
myNetwork.train(myTrainingSet, {
error: 0.03,
iterations: 1000,
rate: 0.3,
momentum: 0.9
});
Setting the momentum to 0.9 will mean that 90% of the previous weight change
will be included in the current weight change.